

When Are Scientific Claims Untrustworthy?
Distinguishing between science and political opinions masquerading as science
By Patrick Brown
Many of us have an intuitive sense that scientific claims to knowledge are inherently trustworthy, and, as outsiders to any subfield, it is intellectually illegitimate to contest such claims. Along those lines, it is common to hear that we live in an era of a war on science, with intentional campaigns and societal forces unjustly undermining expert authority on scientific knowledge.
On the other hand, we also have an intuitive sense that certain claims, even if grounded in science, are more contestable, especially when they carry a valence of politicization. Additionally, there are numerous examples of scientific and science-adjacent experts demonstrating a lack of trustworthiness and reliability. These include the “replication crisis” in psychology (where only 36% of published results could be replicated), high-profile reversals of government dietary advice on topics such as recommended fat intake, and COVID-era reversals of mask-wearing guidelines.
But as an outsider to any subfield, when is it legitimate to contest and debate scientific claims, and when is it not? Daniel Sarewitz and Steve Rayner, two scholars of the relationship between science and society, have discussed several dimensions that help to identify the trustworthiness of claims to expertise and knowledge. Two aspects I find particularly useful are 1) how feedback-rich and falsifiable the knowledge is, and 2) how high the stakes are in terms of broader value-laden ramifications.
Trustworthiness and reliability increase when knowledge producers or experts receive rapid, repeated, real-world feedback and clear performance metrics. Sarewitz and Rayner give examples of pilots and surgeons as “practitioner” experts who occupy this space: their reliability and credibility are derived directly from the large number of feedback-rich trials on which they have built their expertise. Sarewitz and Rayner contrast this with “inappropriate expertise,” where supposed experts may be credentialed, but they seek to advise on matters in which they have not been practically able to accrue a demonstrably reliable track record. An example may be a group of international relations PhDs advising the government on whether to go to war.
Trustworthiness and reliability decrease when stakes are high and values are contested because, in those cases, knowledge generation is highly susceptible to cultural forces and thus motivated cognition. The broader incentive structure and/or often unconscious preferences lead knowledge producers (researchers, scientific institutions, universities, etc.) to begin with a strongly preferred broader conclusion and then gather evidence to support it.
When assessing the general trustworthiness of scientific or science-adjacent claims to knowledge, I have found it useful to arrange these two ideas (slightly reframed and rephrased) in a two-dimensional space:
Below, I put “How testable is the relevant real-world conclusion?” on the horizontal axis.
I put “How strong is the pull toward a preferred conclusion?” on the vertical axis.
At the bottom of the vertical axis, there is a great deal of susceptibility to motivated cognition. Human beings generate scientific knowledge, and human beings are far from being purely rational robots. Thus, scientific knowledge is influenced by ethical intuitions, culture, and peer pressure surrounding researchers, as well as the incentive structure of the scientific funding and publishing systems (see Bias and Science section of Clark et al. 2023).
This means that there will often be pulls towards certain themes and broader conclusions over others, independent of the evidence. Since constructing research papers involves numerous researcher degrees of freedom (such as the research question to ask, the methodological specifics of how to address the question, and the focus of the abstract and title of the paper), there is significant latitude for selection biases to favor preferred broader conclusions over nonpreferred ones.
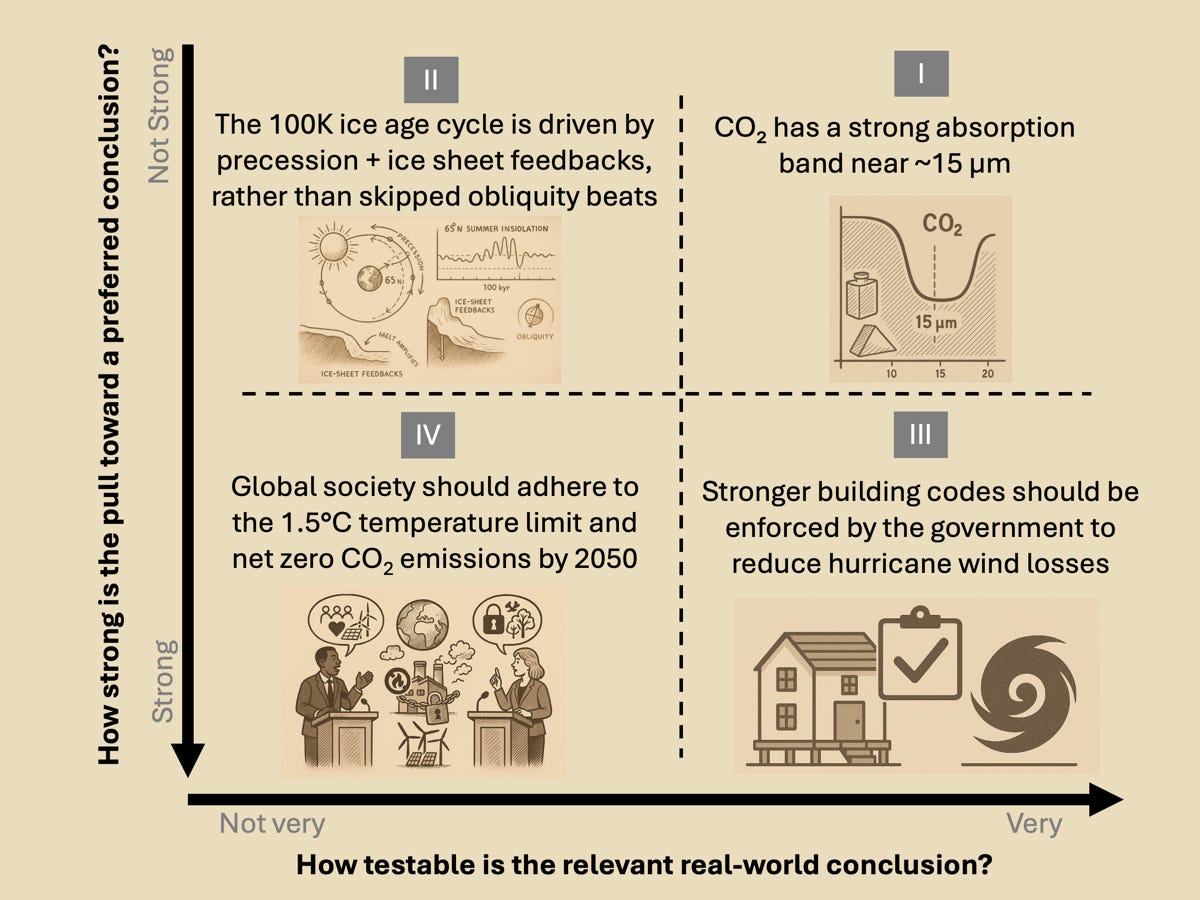
With these two dimensions, we can broadly characterize scientific claims to knowledge into four quadrants (I, II, III, IV).
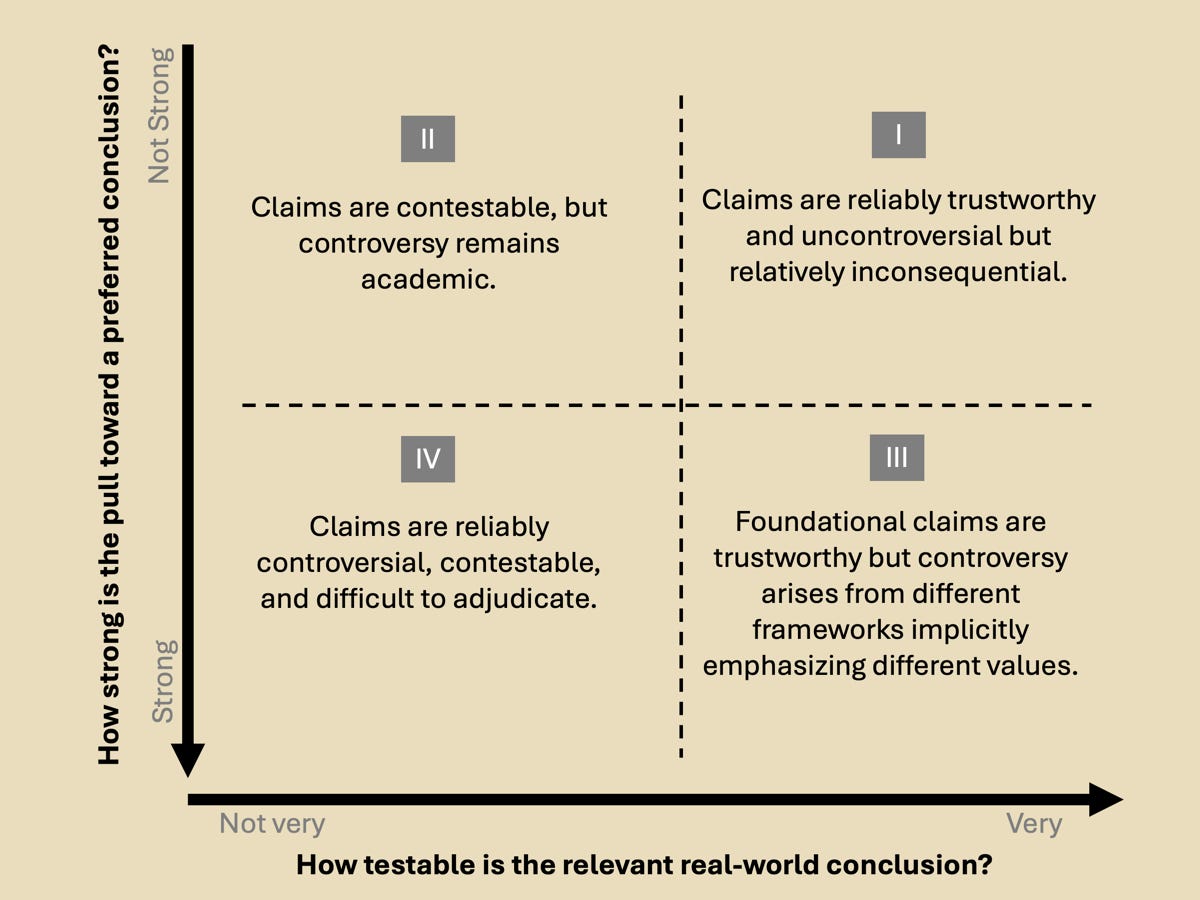
Quadrant I: Claims are reliably trustworthy and uncontroversial but relatively inconsequential.
Quadrant I is the purest realm of the scientific method, where knowledge producers are motivated solely by the pursuit of truth. Here, they engage in an iterative cycle of posing testable hypotheses, deriving predictions, confronting these with reproducible observations/experiments, analyzing the results, and revising or discarding the hypotheses accordingly.
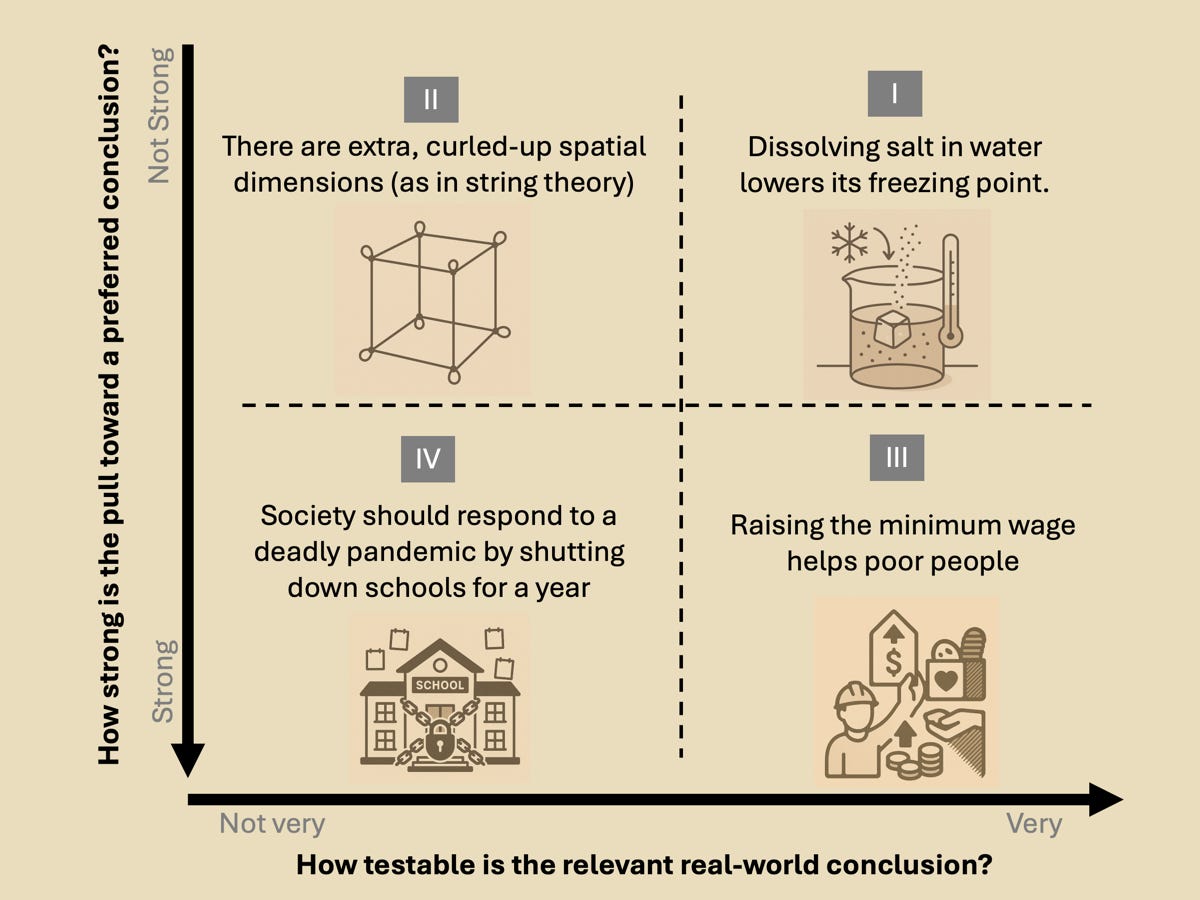
Examples in Quadrant I include the science facts that students learn and practice demonstrating in grade school, such as how dissolving salt in water lowers the freezing point of the water.
However, claims native to quadrant I can extend far beyond archetypal grade school science. The scientific method can be broadly applied to a wide array of claims outside of what are traditionally thought of as scientific domains. In this sense, science is distinct from the subject being studied. Someone can accumulate extensive knowledge in astronomy, earning multiple degrees along the way, without actively practicing science. Conversely, a person working in digital marketing who uses controlled A/B hypothesis testing is engaging in the scientific method. In this case, the digital marketer might have a stronger claim to being a scientist than the person knowledgeable about astronomy.
Quadrant II: Claims are contestable, but controversy remains academic.
In Quadrant II, broader conclusions are not subject to definitive tests either in principle or due to practical limits related to, for example, spatial scale or timescale. Thus, trustworthiness remains provisional and is based on evaluating the internal consistency of claims, indirect evidence, or mathematical elegance.
At the same time, there’s little incentive for the knowledge producers to desire specific conclusions since the broader moral or sociopolitical implications are small. That being said, researchers producing knowledge might still have personal incentives to prefer certain conclusions. This can be because of an idiosyncratic affinity for a particular idea (i.e., a ‘pet theory’). It can also come about due to the inertia in one’s career that may make it practically difficult or psychologically painful to relinquish a long-held position on some academic dispute. For example, if a professor has spent two decades under a particular school of thought and built their “lab” around it, they are inherently going to be more sympathetic to results that support their paradigm.
An example in Quadrant II might be the hypothesized extra, compactified spatial dimensions of string theory. It’s a well-structured idea supported by formalism, but direct, definitive testing is challenging, leading the arguments to focus mainly on theoretical plausibility.
Quadrant III: Foundational claims are trustworthy, but controversy arises from different frameworks implicitly emphasizing different values.
In Quadrant III, core foundational claims and, to a lesser extent, broader conclusions are testable. However, controversy arises due to disagreements on which evidence deserves the most weight and which conclusions to emphasize. Due to incentives within academic publishing or the implicit preferences of researchers, there may be strong publication biases, where certain broader conclusions are sampled much more frequently than others for reasons other than scientific merit.
An example might be the claim that raising the minimum wage helps poor people (keep in mind I’m using a broad definition of “science”). That claim may seem straightforward enough to be tractable, but a problem is that “helps” is a value-laden verb and is interpretable in many different ways. Empirical evidence might show that raising the minimum wage increases wages for those low-paid workers who are actually employed, but has conflicting effects on broader hours worked, employment levels, or small-business survival. One might argue (with data and models) that a minimum wage narrowly raises incomes in lower terciles in the short term but stifles economic growth in the long term, eventually harming society overall, including poor people. Whether this policy “helps” depends on which outcomes are prioritized, the specific populations considered, and the time frame of concern. These debates may seem to focus only on the technical aspects of the question, but they also incorporate ethical and value disputes that are inherently political. These political disputes are not so much about fundamental facts but rather are about “who gets what, when, and how” [Lasswell (1958) via Pielke Jr. (2004)].
Quadrant IV: From the perspective of desiring neat, straightforward answers, Quadrant IV is a mess.
Claims are reliably controversial, contestable, and difficult to adjudicate because they are framework and model-dependent, difficult to test, embed value-laden assumptions, and are strongly susceptible to personally and culturally-influenced motivated cognition by the experts producing the knowledge. The same suite of evidence or underlying facts can be legitimately assembled into coherent narratives that seem completely at odds with each other, and there is no straightforward way to adjudicate which emphasis is “correct” (See Sarewitz, 2004 for a full academic treatment of this issue).
An example could be the claim that society should respond to a deadly pandemic by shutting down schools for a year. The counterfactuals are highly uncertain, objectives are numerous and incommensurate (mortality, learning, equity, livelihoods). Rapid, controlled, clear tests don’t exist, and many interests influence the desirability of different conclusions.
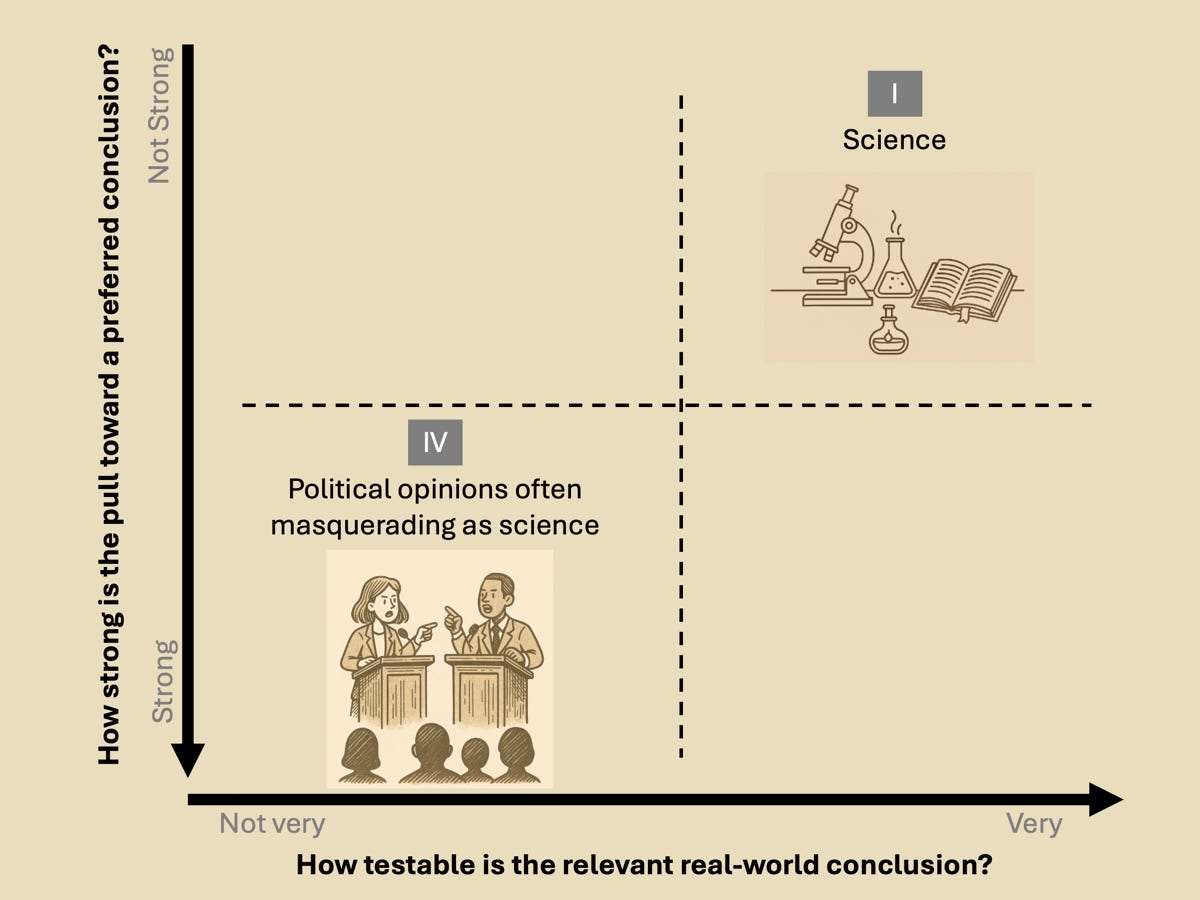
The problem of conflating Quadrant IV with Quadrant I
It should be clear from the descriptions above that claims native to Quadrant I can be taken at face value and considered reliably trustworthy, whereas claims native to Quadrant IV are inherently contestable and may be quite dubious if not properly contextualized. Arbitrarily dismissing a claim from Quadrant I can legitimately be referred to as science denial (unless you have devised some revealing new hypothesis test), while challenging or debating claims from Quadrant IV, even without special expertise, should be fair game.
As the examples above indicate, Quadrant IV often overlaps substantially with what we tend to classify as political claims (with scientific or technical underpinnings). Crucially, as stated above, politics is about deciding “who gets what, when, and how” [Lasswell (1958) via Pielke Jr. (2004)]. Thus, politics is not very susceptible to the scientific method. What hypothesis test would definitely tell us how to value various tradeoffs properly and what any individual, entity, or group “deserves”?
Most of us in liberal democracies believe that these political decisions should not be made decisively behind closed doors by technocratic expert panels but rather be discussed openly in public debates, op-eds, and through democratic decision-making. This would all be well and good if the distinction between Quadrant I claims and Quadrant IV claims were delineated clearly.
However, there is a large and seemingly increasing desire for ostensibly scientific institutions and expert bodies to overreach and use the epistemic authority granted to science by the qualities of Quadrant 1 to attempt to make authoritative statements in Quadrant IV. In its most extreme form, this amounts to dressing up political opinions as if they were scientific facts.
It is, of course, alluring to present political opinions as scientific facts if you see yourself as a scientist or believe that science inexorably supports your political views. This approach makes your stance appear not just as another opinion but as a privileged one rooted in objectivity and rationality.
Examples are too numerous to catalog, but one illustrative one in this context would be the paper “Paris Climate Agreement passes the cost-benefit test” published in Nature Communications in 2020. I have no problem with doing this kind of work, per se, as I have published on this exact same question (though with a more descriptive and, dare I say, accurate title). However, I recognize that these kinds of publications can vastly oversell their claims to authority. They blur the lines of epistemic authority because they are written in the language of science, utilizing equations and a formal third-person academic style (which gives the impression that the knowledge is independent of the human authors who wrote the paper). They are also published in “scientific” peer-reviewed journals, which creates the impression that broader conclusions have been extensively vetted and can thus be considered more or less “true” (even if provisional and subject to refinement).
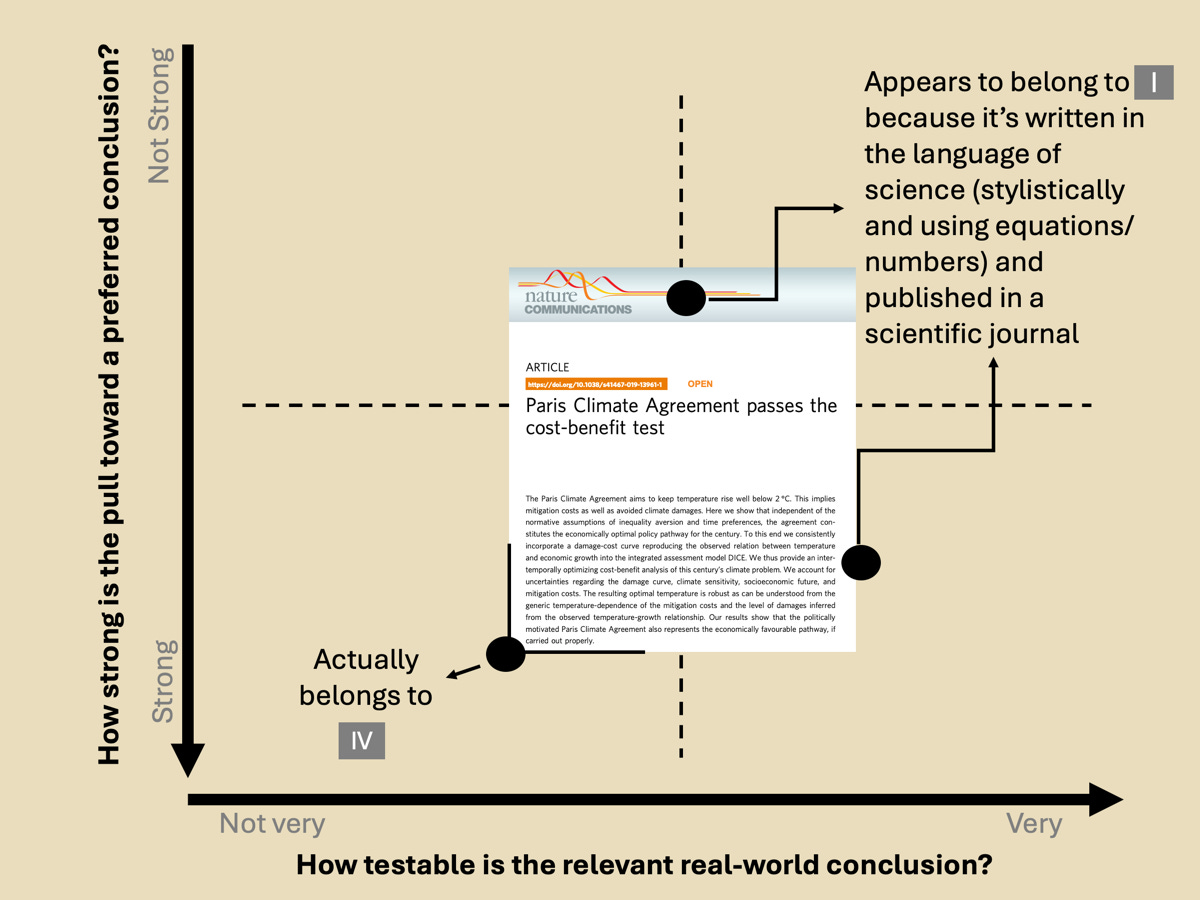
However, a little reading and critical thinking reveal that broader conclusions of papers like this rely upon layers of stacked assumptions and embed disputed ethical and value questions. They involve attempting to quantify and weigh incomparable outcomes across different people, groups, and species over space and time while simultaneously projecting future socioeconomic, political, and technological changes.
For example, how should one weigh the possible long-term extinction of warm water corals against near-term increased human energy access and thus poverty reduction in low-income countries? Attempting to convert this question into a numerical one amounts to false precision and the fallacy of misplaced concreteness. As David Roberts put it when discussing a similar kind of modeling:
“These are social and ethical disputes being waged under cover of math, as though they are nothing but technical matters to be determined by ‘experts.’ But social and ethical judgments should be made in an open, transparent way, not buried in models as inscrutable parameters. I mean, we’re talking about how much we value our children and grandchildren. Surely that’s a matter for democratic discussion and debate!”
This paper is not an exception. Many disagreements in climate science and its downstream policy implications are presented as mainly technical, suggesting they could hypothetically be resolved by more or better science (or by focusing on ‘good’ science and dismissing ‘bad’ science). However, many of these disagreements are actually ethical or moral, leading to the emphasis of different facts and thus divergent broader conclusions.
For example, conventional climate science and climate policy, as represented by the United Nations Intergovernmental Panel on Climate Change, are heavily guided by the underlying goal of the United Nations Framework Convention on Climate Change of “avoiding dangerous anthropogenic interference with the climate system.” This framework emphasizes, for example, the precautionary principle applied specifically to climate change over cost-benefit analysis of various energy systems and their alternatives, as well as the intrinsic value of an unchanging climate over a centering of the relationship between energy and human welfare.
On this point, it was telling that in the foreword of the recent controversial United States Department of Energy (DOE) report on climate change impacts, Energy Secretary Chris Wright was explicit about reorienting the moral framing of climate change to be about the net effect of fossil-fueled economic and technological development on people, writing things like “Climate change is real, and it deserves attention. But it is not the greatest threat facing humanity. That distinction belongs to global energy poverty.”
Nevertheless, combatants in these debates like to argue that only their opponents‘ conclusions are heavily influenced by moral frameworks (or more pejoratively, “ideology”), whereas their own conclusions spring inexorably from the underlying scientific facts. This was emphasized in the Department of Energy report with sentiments in the forward accusing mainstream climate science of recommending “misguided policies based on fear rather than facts” and it was emphasized in various retorts to the DOE report, where the claim was that ideological bias caused the report to get the underlying facts wrong, which then led it to the wrong conclusions.
This all gives the impression that if we could just eliminate “ideological bias,” then pure “science” would illuminate a direct path forward. Ultimately, though, these are Quadrant IV discussions where a shared set of facts can be marshaled to support arguments for diametrically opposed broader conclusions. There is no such thing as eliminating ideological bias because all prescriptive recommendations on a course of action rest on some contestable moral framework, and many of the most important claims are very difficult to test.
Thus, it would be clarifying to focus on surfacing the ideological and moral disagreements that drive the pull towards different preferred conclusions and acknowledging why claims are difficult to adjudicate. In doing so, it would be easier to recognize that these Quadrant IV claims are inherently contestable and will always be.